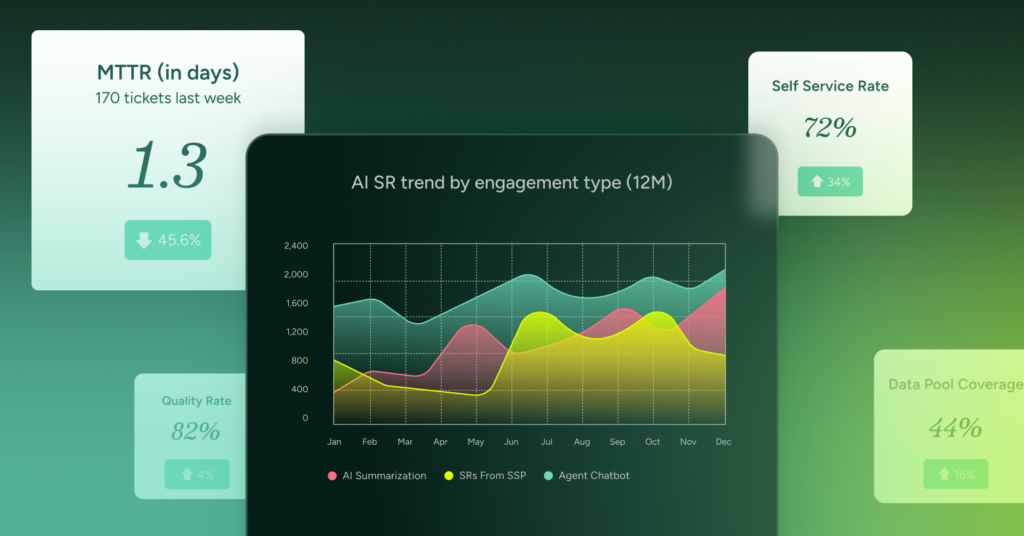
7 Ways to Diagnose IT Incidents and Problems

You need to train and mentor service desk and IT support staff in techniques they can use to diagnose incidents and problems. They won’t become good at this just because they have the right technical knowledge and ITSM process skills.

Every IT organization has processes for managing incidents and problems. Often these are based on ideas from ITIL, the world’s leading best practice for IT service management. According to ITIL, an incident is “An unplanned interruption to an IT service or reduction in the quality of an IT service…” and a problem is “A cause of one or more incidents….” The incident management process helps to restore normal service, and the problem management process helps to reduce the impact of future incidents.
Incident and problem management processes define the steps people should take to manage and resolve issues, and they nearly always have a box labelled “Investigation and Diagnosis” (or something very similar) where something magical is supposed to happen.
For the people whose job it is to fix things when they go wrong, the most important activities are diagnosing the issue, and working out how to fix it. Of course, they have to do all the other things in the process, like update records and notify users when they have a resolution, but most of their time is spent doing “Investigation and Diagnosis.”

So, if you diagnose incidents and problems, or manage people who do, then I’m here to let you know that there are specific approaches available that will be of use to you. You should learn them and be able to use them when appropriate. Here are some that I have found particularly helpful, though the list is not exhaustive.
Approaches to Diagnosing Incidents and Problems
Some of the approaches described here are used just for diagnosis, others have a wider application. If you have a good understanding of all of them it will help you to decide which approach is most appropriate for your current situation.
1. The Richard Feynman Approach
The famous physicist Richard Feynman is supposed to have developed a process for solving physics problems that looked like this.
- Write down the problem
- Think very hard
- Write down the answer
This process has the advantage of simplicity, but is probably not going to work well for those of us who aren’t clever enough to win a Nobel Prize. So, I suggest you only use this method if you are VERY clever, or if your problem is simple and you have access to all the knowledge and information you need. You can also use this approach in conjunction with any of the other approaches below, it’s always a good idea to think hard before you jump to conclusions.
2. Timeline Analysis
This is such an easy way to investigate an incident or problem that it barely deserves a name. You simply list everything that happened in time order and then look for patterns. What is important is that you get all the data from multiple sources and then sort it by date and time, regardless of where it came from. Your timeline may have entries from system logs, emails, service desk records, and many other sources. This simple approach is surprisingly effective at building a complete picture of what’s been going on.

Figure 1- Example timeline analysis
I almost always start with timeline analysis, because it’s often enough to let me understand what happened, and it also ensures I have all the information I need if a more sophisticated approach turns out to be necessary.
3. Kepner-Tregoe Problem Solving
Full disclosure: I have to declare an interest here as I used to teach this proprietary approach to problem solving. But I honestly do think that it’s incredibly effective.
It’s a structured approach to problem solving, where you define the problem across a number of different dimensions (what, where, when, extent) and you also bound the problem by identifying what is NOT failing. You can then review the distinctions between these to identify possible causes.
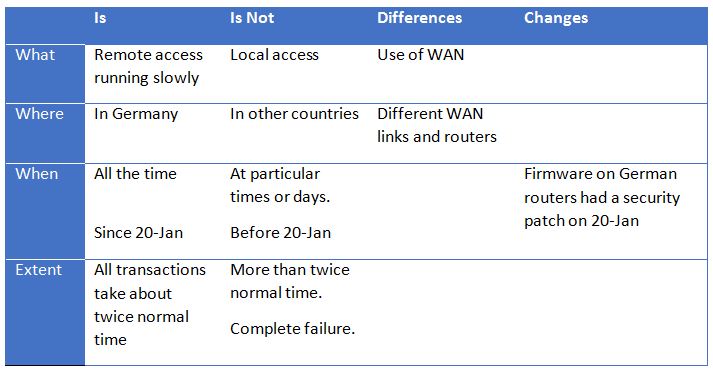
Figure 2- Simplified example use of Kepner-Tregoe problem solving
4. Ishikawa or Fishbone Diagrams
An Ishikawa diagram is a way to progressively break down potential causes of a problem. Causes are grouped into categories, to help understand and visualize the relationships. You can create such diagrams to help identify all the potential causes of an issue during diagnosis. But they can also be created as part of the product documentation so they’re already available to help with troubleshooting any issue that occurs.

Figure 3- Simplified example Ishikawa diagram for an email service
5. Knowledge-Centered Support
Knowledge-Centered Support is primarily a methodology for capturing and managing information, which support personnel and service desk staff need. If the required information is made available to the people who need it, at the time it is needed, this can lead to rapid insights, and fast resolution of incidents and problems. People who have the right knowledge available to them are much more likely to be able to use Richard Feynman’s method of problem solving!
6. Swarming
Swarming is a collaborative approach that changes many aspects of incident management, not just the diagnosis phase There is no escalation to higher levels of support. Instead, anybody who might be able to help, joins the swarm. This means that many people, who may come from different parts of the organization, and who between them have an extensive range of relevant knowledge and skill, collaborate to solve the issue. The swarm may use some of the other approaches described in this blog, but the key point is that collaboration between many people with varied yet relevant skills, tends to result in faster and more accurate diagnosis and resolution of incidents and problems.
You can find some more information about swarming in this blog by Jon Hall.
7. Standard+Case
Standard+Case is another approach that changes many aspects of how incidents are managed. It was developed by Rob England, and is described in this article, and in a separate publication that you can find linked from there. The basic idea of Standard+Case is that standard activities should be managed by following a well-defined process, but that more complex activities require case management, using techniques that have been developed in fields such as health, social work, law, and policing. This approach enables high levels of efficiency for routine incidents, but provides the ability to handle more complex incidents in a more versatile manner.
Conclusion
You need to train and mentor service desk and IT support staff in techniques they can use to diagnose incidents and problems. They won’t become good at this just because they have the right technical knowledge and ITSM process skills.
There are lots of different techniques and methodologies that staff could use, and you should try to understand a wide range of different approaches. Some may not be applicable to your environment, but the more familiar you are with a variety of approaches the more likely you are to be able to deploy the right one when you need it.
Did you find this interesting?Share it with others:
Did you find this interesting? Share it with others:

Why your ITSM was built for a world that no longer exists
SysAid’s AI Agent Center: Command and control for your AI Agents
Take control of software license compliance with SysAid License Manager

Why IT teams are afraid to innovate, and what it’s costing them

The hidden cost of institutional knowledge in IT