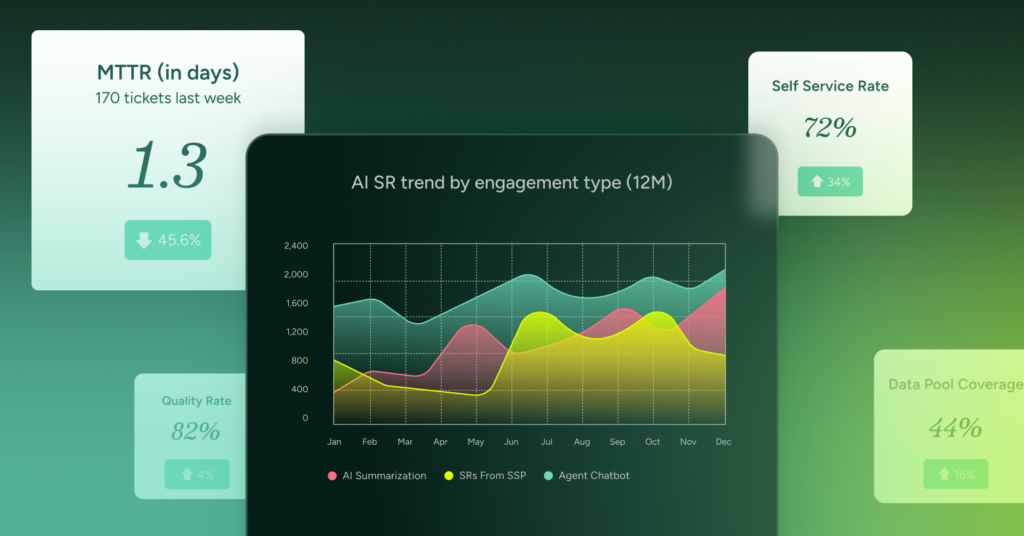
Problem Management: Most Problems Don’t Have a Single Root Cause


If your problem management just identifies one root cause for each problem, you’re missing out on lots of opportunities to improve.
One of my clients had a problem that caused lots of incidents. They investigated the problem and identified the root cause. It was, they agreed, a bug in a software application that had been developed in-house. They fixed the bug and closed the problem.
This is typical of what I see happening in problem management, and superficially it looks OK. But actually, it isn’t good enough, because you need to ask a lot of awkward questions if you want to understand what really happened.

Thorough investigations demand answers to awkward questions
A thorough investigation of this problem would have asked lots of awkward questions like:
- Why was the software incorrect in the first place?
- Was the specification correct?
- Was this a simple coding error?
- Was there a failure to understand the business process?
- Did the developer correctly understand how the user would interact with the software?
- Did the software developer have all the information they needed?
- Did the software developer have the correct skills and experience?
- Why was the software bug not detected before deployment?
- Did a peer review take place? Was the peer reviewer competent and experienced enough? Did they have the information they needed?
- Was testing performed? Was the test environment fit for purpose? Was the testing scope sufficient?
- Why did it take so long to identify that there was a problem after the first incident(s)?
- Did the service desk agents have the skills and knowledge they needed to identify problems?
- Did the service desk tool have the capability needed to assist in identifying multiple related incidents?
- Was there a process for reviewing incidents to ensure that problems were identified? Was this process effective?
- Why did it take so long to diagnose the problem after it had been identified?
- Were people with the right skills and knowledge available to diagnose the problem?
- Was all the information needed to diagnose the problem available when and where it was needed?
- Was the problem prioritized appropriately relative to other work?
- Why did the problem cause so much business pain after it had been identified?
- Was a satisfactory workaround documented?
- Were future incidents needing the same workaround quickly and consistently identified?
- Was the workaround implemented quickly and effectively after each incident?
- Did someone review the workaround after it had been used to identify how it could be improved?
- Why did it take so long to deliver a software fix into production?
- Were appropriate resources available to develop and test the solution?
- Was this prioritized appropriately relative to other work?
- Did the process for testing and deploying the solution introduces unnecessary delays?
How many causes does one problem have?
The questions I listed above are typical of what you need to ask if you want to understand
- Why the problem happened
- Why the problem had such an impact
- How to reduce the likelihood of similar issues causing problems in the future
The fact is that almost any problem has many causes. Some of them may be technology-related (like a software bug, or a faulty laptop), and ‘information and technology’ is indeed one of the dimensions of service management identified by ITIL 4. But there are three more dimensions of service management you need to consider if you want to thoroughly investigate the causes of a problem. Because causes may be related to ‘organizations and people’ (skills, competence, knowledge), ‘value streams and processes’ (development, testing, incident management) or even ‘partners and suppliers’ (contracts, relationships).
The first step towards improving is knowing what to improve
When you think about solving problems by uncovering the “root cause” it’s likely that you’ll identify a technology-related issue, fix it, and stop there. If you take this approach, the chances are that you won’t notice any other things that didn’t work as well as they could have, and as a result, you’ll miss many opportunities to improve and to reduce the number and impact of problems you see in the future.
What’s worse is that if you don’t take the time to identify your own weaknesses you can all too easily find yourself caught up in an endless, and unnecessary cycle of fixing one “root cause” after another.
Keep an improvement register, and make sure that every problem investigation is done thoroughly, taking into consideration all the dimensions of service management. When you take this approach, every investigation will throw up many improvement opportunities that you can identify and log. Whether or not to invest the resources needed to address them is a decision you can take later, but once they’ve been identified and prioritized, at least you know what they are and have thought about the damage they might do if left unaddressed.
If you need more information about improvement registers and continual improvement, here are some blogs and papers I have written:
- 5 Tips to Help Prioritize Your CSI Improvements
- The Help You Need to Adopt Continual Service Improvement
- Managing a Continual Service Improvement Register
How can you identify causes of problems?
There are lots of different techniques for identifying things that cause problems. I’ve written a blog titled 7 Ways to Diagnose IT Incidents and Problems, that describes some of the more popular ones. Here’s a quick summary if you don’t have time to read the blog.
- The Richard Feynman Approach: Write down the problem; think very hard; write down the answer
- Timeline Analysis: List everything that happened, in time order; look for patterns
- Kepner-Tregoe Problem Solving: Document the problem in terms of What, Where, When and Extent; identify what is not failing as well as what is; list differences and changes; identify possible causes; verify the true cause
- Ishikawa or Fishbone diagrams: Draw a diagram showing all the possible contributory causes and the links between them
- Knowledge-Centred Support: Capture and manage information as part of routine incident handling
- Swarming: Collaborate rather than escalating
- Standard+Case: Distinguish between routine work and more complex situations
Two more techniques that I also find helpful are
- Ask a friend: Don’t just work by yourself, chat to your colleagues and draw on their knowledge and expertise. You could call this “informal swarming”
- 5 whys: This technique from Lean encourages you to repeatedly ask Why, rather than accepting the obvious root cause
Of course, you don’t have to pick just one of these, you can use a combination of them as appropriate to your situation.
Summary
If your problem management just identifies one root cause for each problem, you’re missing out on lots of opportunities to improve. You can use the four dimensions of service management described in ITIL 4 to help ensure your investigations cover all aspects of service management; organizations and people, partners and suppliers, value streams and processes, and information and technology. This should, in turn, help ensure that your problem investigations don’t just fix a technical “root cause” but also contribute to a culture of continual improvement by uncovering issues to be added to your continual improvement register.
Did you find this interesting?Share it with others:
Did you find this interesting? Share it with others:

Why your ITSM was built for a world that no longer exists
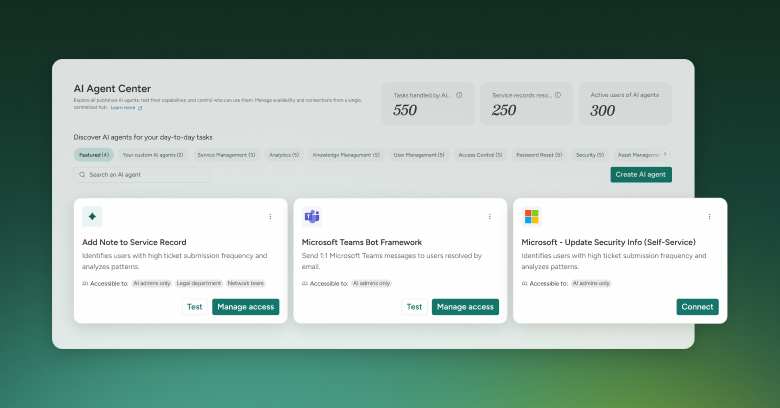
SysAid’s AI Agent Center: Command and control for your AI Agents
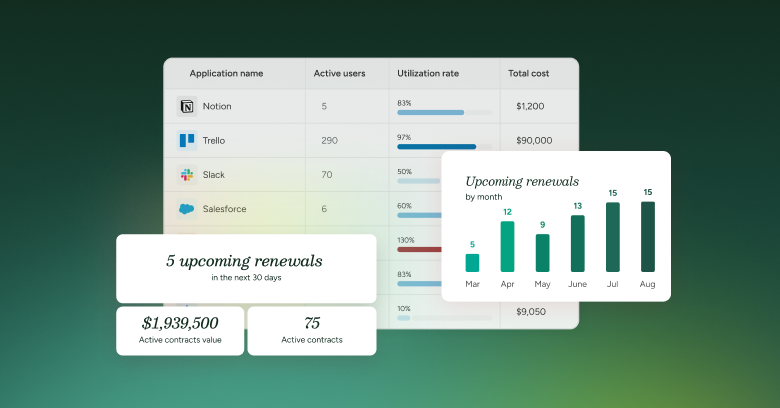
Take control of software license compliance with SysAid License Manager

Why IT teams are afraid to innovate, and what it’s costing them

The hidden cost of institutional knowledge in IT