3 Steps to a Practical, Real-World On-Ramp to DevOps

Everyone seems to be talking about DevOps but, if you are new to it, it might all seem a little overwhelming. This blog directs you to three steps to take in starting with DevOps that will help your organization and its people to begin in the right places and with the right things.

One of the hardest things about DevOps is knowing where to begin. This is because to “do DevOps” you seem to have to suddenly start doing a lot of new people, process, and tool things all at once. For example, you need applications and infrastructure to be automated. So:
- Are your applications and infrastructure automatable?
- Do you have the right tools?
- Do you have the right skills?
- If not, what do you have? Where and what are the gaps?
In an organization that doesn’t use DevOps today, where applications are launched over a gaping chasm – propelled, sometimes shot down, via manual ITIL-based processes – it has become good practice to adopt the following three-step approach. Doing it this way means not trying to swallow the pineapple in one gulp, instead slice it into three:
- DevOps-ify the application release stream, then
- DevOps-ify the infrastructure release stream, then
- Release whole environments/stacks.
A Cautious, Practical Three-Step Approach to Apply DevOps
This three-step approach can be visualized in the diagram below. The reality might have some overlaps, but this is generally a clean approach:
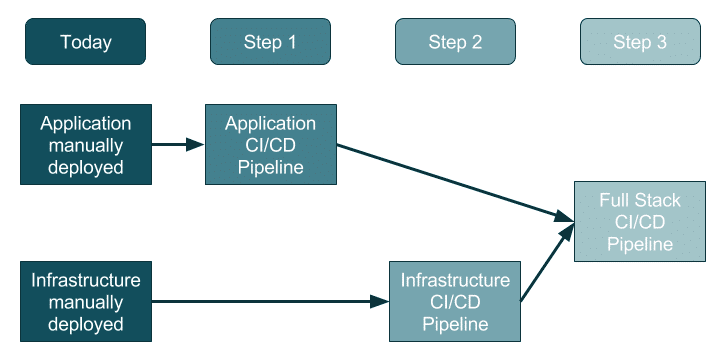
Allow me to explain…
Step 1: Creating the Application Pipeline
Regardless of the type of application, the pipeline looks – at a distance – very similar.
The goal is to weave application releases into a new coordinated process that looks something like this:
- The developer makes changes locally to his/her laptop/PC/Mac, and upon completion (including their testing etc.) issues a Pull Request.
- Code-review kicks in now and the developer changes are reviewed, accepted, and a new release can be created.
- Someone, or the system, runs a procedure to create a Release Artifact, which could be a Java JAR file, a Docker File, or any other kind of Unit of Deployment.
- Someone, or the system, copies the artifact to the web or application servers and restarts the instances.
- Database migrations/updates may be additionally applied, although the database is often left outside of the application release process.
This process evolves into an automated application-only continuous integration and continuous deployment (CI/CD) pipeline by using a toolset to automate the process as shown in the diagram below:
A Typical CI/CD Pipeline
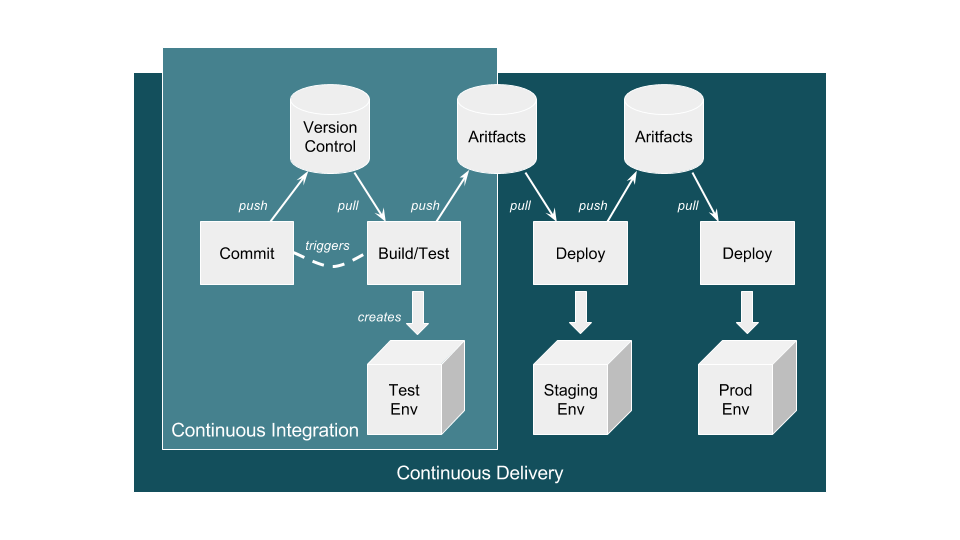
Source: https://ukcloud.pro/
However, be aware that this isn’t ideal (yet), because at this point the application alone is being released (injected) into existing environments.
Why is this potentially an issue? It’s because if the developer has altered the local environment as well as the application, but these local environment changes are not part of the release, then they’re not in version control. And, if they are not applied at the same time as the application, then the application will break and the common argument occurs: “Well, it works on my machine!” The solution is for application and infrastructure releases to be synced – and hence steps 2 and 3.

Step 2: Creating the Infrastructure Pipeline
Ideally, the infrastructure team will have learned, or is learning, from the developer team’s DevOps and CI/CD pipeline journey and can expand and adapt it for the infrastructure (and, increasingly today, the infrastructure is a public cloud).
There are some differences with the infrastructure pipeline, specifically around units of deployment that are now the infrastructure layers in environments, the things that surround an application such as the DNS, load balancers, the virtual machines and/or containers, databases, and a plethora of other complex and interconnected components.
The big difference here is that the infrastructure is no longer described in a Visio diagram: it is brought to life in code, in a configuration file, in Version Control – this is Infrastructure as Code (IAC).
Before this, a load balancer was described in Visio diagrams, Word documents, and Excel spreadsheets of IPs and configurations. This is now swapped to describing everything about the load balancer in a configuration file. For instance:
An Example AWS CloudFormation Configuration for a Load Balancer
{
"Type": "AWS::ElasticLoadBalancing::LoadBalancer",
"Properties": {
"AccessLoggingPolicy" : AccessLoggingPolicy,
"AppCookieStickinessPolicy" : [ AppCookieStickinessPolicy, ... ],
"AvailabilityZones" : [ String, ... ],
"ConnectionDrainingPolicy" : ConnectionDrainingPolicy,
"ConnectionSettings" : ConnectionSettings,
"CrossZone" : Boolean,
"HealthCheck" : HealthCheck,
"Instances" : [ String, ... ],
"LBCookieStickinessPolicy" : [ LBCookieStickinessPolicy, ... ],
"LoadBalancerName" : String,
"Listeners" : [ Listener, ... ],
"Policies" : [ ElasticLoadBalancing Policy, ... ],
"Scheme" : String,
"SecurityGroups" : [ Security Group, ... ],
"Subnets" : [ String, ... ],
"Tags" : [ Resource Tag, ... ]
}
}
Whenever this file is changed in Version Control, such as changing the subnets a load balancer can point to, then the automation engine can update an existing infrastructure environment to reflect that one change, and any dependencies that change.
It also means that you can apply this template to multiple environments, just by changing the environment name from staging to production for example, and be very confident that all environments are consistent – from the developer laptop to production.
It is also possible to make the templates dynamic to change their behavior according to the environment, so in production the environment will scale out across three datacenters, but on a developer’s laptop it will use a local VirtualBox single-system.
Step 3: Creating the Full Stack Pipeline
The goal of a full stack pipeline is to ensure that the application and infrastructure changes over time are in sync, both in Version Control and the release deployments across each pipeline stage. And a developer should never say, “It worked on my laptop!” when a release fails in production.
The popular CI/CD tools can now automate the full stack because, especially when using public clouds with mature APIs and tools, everything is programmable. This means everything can be captured in Version Control, and the same configuration can use dynamic input parameters to build an environment on a developer’s laptop, or a QA system in the cloud, or updates to production.
Imagine this DevOps nirvana: a developer makes an application change that also requires a change to the database, to the web instance scaling configuration, and to the DNS. All of these changes are captured in one Version Control branch and the developer builds a system on his/her laptop from this branch, and tests it.
This is what Platform-as-a-Service systems, such as AWS Elastic Beanstalk, can do. By adding an environment configuration file inside the same code base as your application, you can ensure that you have bound your application to the infrastructure.
AWS Elastic Beanstalk Example
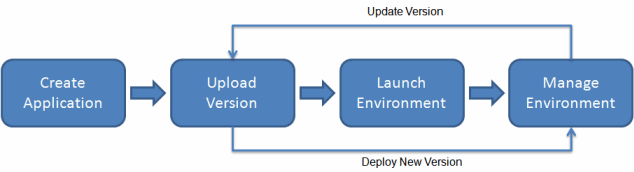
Source: What is AWS Elastic Beanstalk?
This is the target end goal, though it takes a lot of practice, and learning, to get there. But it can be fun and very rewarding – it’s very satisfying to watch a build and a deployment, seeing the automation use tags and dynamic configurations to build, or update, the target environment with application and infrastructure changes.
So that’s the three steps – what else would you offer as advice for companies on-ramping to DevOps?
Did you find this interesting?Share it with others:
Did you find this interesting? Share it with others:

Your IT team is losing 35% of its capacity to manual work

IT burnout is at a breaking point, and we have the numbers to prove it.

Shadow IT is quietly breaking your software license compliance and your security posture

From firefighting to future-proofing: Using Mean Time to Resolution to build a proactive IT culture

Kicking off 2025: SysAid Wraps Up 2024 With Prestigious Recognitions from Gartner Digital Markets in 2024

Are You Missing Out On the BI Opportunity with Your ITSM Tool?
